Contents
- When a type can't make the cut
- The spec got cheap to write — not cheap to trust
- The branches that survived review
- Where the cheap cut stops
- The political problem
- Start cutting
- References
When a type can't make the cut
The invoice was voided. The money was already captured.
The type was right. Every test was green. There was no database constraint forbidding it — not because anyone decided to skip one, but because nobody knew this state could happen. It lived in the timing: void the invoice, then a payment webhook arrives late, confirming a capture already in flight. The webhook handler checked payment_succeeded? but not voided?. The write went through. The ledger showed nothing owed; a real charge sat unreconciled.
I found it by asking a checker whether that joint state was reachable. The path it handed back — draft → finalized → voided → voided + paid — was a sequence nobody had drawn on a whiteboard, and no test had ever simulated. That's the whole move: the checker doesn't just enforce the fence, it tells you which fence to build — which forbidden combination is actually reachable, so you know to go add the CHECK for it.
Types delete bad states. Constraints delete bad combinations. But you can only constrain the states you know exist — and neither touches the order events arrive in.
This is Part 2. Part 1 covered the two cheapest cuts — a discriminated union, a database constraint — that make illegal states unspellable. Here we handle the states you can't delete, only verify.
But some bugs don't fit in a type or a CHECK. Maybe the state space is
genuinely huge. Sometimes the business won't let you shrink it. Or the rule is
about the order moves happen in, not any single row. So you keep cutting, with
a small ladder of verification tools that each cost more and buy a stronger
guarantee than the last. They look unrelated — a state machine, a pairwise
generator, a model checker — but every one is asking the same question with more
rigor: can a bad state happen, and how sure are we? You don't run all four. You
climb as far as your bugs make you and stop at the first rung that catches them.
Cheapest first:
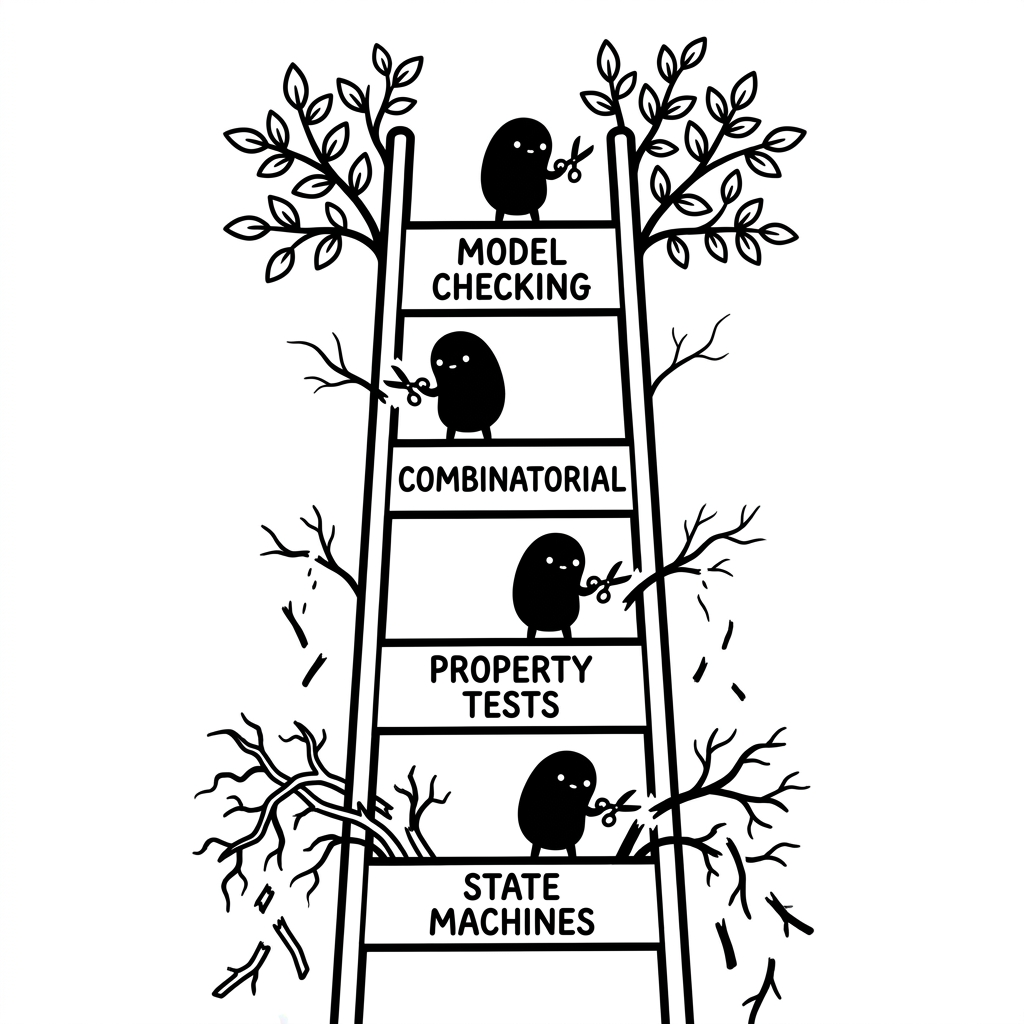
Step 1 — State machines
Someone sets isPublished to true. Forgets to clear isArchived. The type allows it, nothing checks it, and the "archived" banner appears over a live listing. The boolean got set; the invariant didn't.
A state machine makes that move unreachable before it happens — not by checking the value after the fact, but by declaring which moves exist at all. Draft can become published. Published can be archived. Archived can't go back to draft. Ever. Nothing in the codebase needs to "remember" the rule; the machine refuses anything not in the table, and there's no table entry for "published and archived at once."
The machine is more confident about this than the roadmap.
▶Step 1 in Ruby (AASM) and TypeScript (XState)
# Ruby with AASM
class Order < ApplicationRecord
include AASM
aasm do
state :draft, initial: true
state :published, :archived
event(:publish) { transitions from: :draft, to: :published }
event(:archive) { transitions from: [:draft, :published], to: :archived }
# Note: no transition back from :archived. Once archived, terminal.
end
end
order.publish! # OK
order.archive! # OK from draft or published
archived_order.publish! # AASM::InvalidTransition — the machine said noSo now the machine is the documentation and the enforcement at once. The reachable states are finite, they live in one place, and anything not in the table just gets refused. You write the rules down once and the machine runs them for you. The graph is the type.
Step 2 — Sample the space
When the space is too big to list and you can't shrink it further, you sample it — two ways, one blunt and one sharp.
The blunt one is property-based testing, and I ignored it for years — writing good properties always felt like more work than just picking a few inputs by hand. That was a mistake. The pitch is simple: instead of "input X → output Y," you write down a property that should hold for any input, and the framework throws hundreds of random cases at it trying to break it — fast-check (TypeScript), Hypothesis (Python), PropCheck (Ruby); the stateful variants even walk random sequences of moves. It runs circles around the three cases you'd have picked yourself. But random has a blind spot: the one pair that sinks you is exactly the spot no throw ever lands.
I've shipped the other half of that blind spot, too: a bug that lived only in a state our test data never built. Our content came in two shapes with different time rules, and the seed scripts only ever generated one — so the other branch was never once exercised in CI, and an exception that could only happen there shipped green. The state space our tests explored was a strict subset of the one prod ran in.
The sharp alternative fixes that blind spot by construction — and the number is almost offensive.
Twenty feature flags is 1,048,576 possible configurations. Testing every pair of them takes ten test cases.
1,048,576 → 10. Every pair of twenty flags, covered in ten configs.
Not a thousand. Ten. That's not a trick — decades of fault data say failures cluster in low-order interactions. NIST's analysis of real bugs found that testing every pair catches 70–97% of bugs, and across every fault dataset they studied, none needed more than six factors interacting at once. So you don't cover a million configs; you cover the pairs, and the pairs fit in ten rows. A covering array is a small set of configs that guarantees every pair of values appears at least once. Need to catch a specific three-way combination? Bump the strength to t = 3 and it lands in the rows by construction.
Don't take it on faith — there's a real two-flag bug hiding below. Test six configs at random and watch it sometimes ship green; then run the six-row covering array and watch it get caught every time:
Covering arrays
32 configs → 6

dark-mode and pdf-export each work fine. Turn on both and the PDF renders white-on-white — invisible. The bug hides in one pair of flags, among 32 configs. Can you catch it?
1 = on · · = off · 🐛 = the bug
Almost nobody does this: GitLab's open-source repo ships ~500 feature flags, tests them one at a time, with no combinatorial strategy at all — and they're more disciplined about flags than most of us. You're in good company. So is the bug.
▶Generators, constraints, and the one caveat
The generators are off-the-shelf — NIST's own ACTS and Microsoft's PICT on the command line, or a one-line library right inside your test runner.
Three booleans — eight combinations — need just four rows to hit all pairs:
A B C
0 0 0
0 1 1
1 0 1
1 1 0Check it: every pair of columns shows all four of 00, 01, 10, 11. The
magic is how that scales. Covering-array size grows with the logarithm of
the parameter count, and exponentially only in t — the interaction strength
you're covering — not in the number of parameters. That's why twenty flags
collapse to a handful of rows instead of a million.
You write one text file — PICT, Microsoft's generator, is the usual default:
dark-mode-for-real: on, off
ai-everything: on, off
temporary-fix-2019: on, off
layout: single-page, multi-step
IF [ai-everything] = "on" THEN [dark-mode-for-real] = "off";pict model.txt prints the rows; each row is one test config. Constraints
(the IF/THEN) keep it from generating combinations you've already made
illegal. NIST's own ACTS tool
does the same up to 6-way, with a GUI or CLI.
The easiest path skips the shell-out entirely: a covering-array library generates the rows in-process and hands them straight to your test runner's parametrize hook — no binary, no parsing. In Python with allpairspy:
from allpairspy import AllPairs
import pytest
flags = {
"dark_mode_for_real": [True, False],
"ai_everything": [True, False],
"temporary_fix_2019": [True, False],
}
@pytest.mark.parametrize("cfg", AllPairs(list(flags.values())))
def test_checkout(cfg):
dark_mode_for_real, ai_everything, temporary_fix_2019 = cfg
assert checkout_works(dark_mode_for_real, ai_everything, temporary_fix_2019)Three flags, all pairs, in the handful of cases the table above predicts — just a decorator, no new infrastructure. Pick whichever fits your stack:
| Where you run it | Tool |
|---|---|
| CLI, any language | PICT · NIST ACTS (≤ 6-way) |
| Python test runner | allpairspy |
| TypeScript / browser | covertable · pict-pairwise-testing |
One mechanical caveat: pairwise is still sampling. It provably covers every
pair, but a fault that only fires on a specific three- or four-way combination
can slip through (a medical-device study found a real four-way one). Bump to
--o:3 for anything safety-critical; the cost is more rows, not a different
tool.
And pairwise is still sampling, not proof — combinatorial testing is the consolation prize. If you can collapse those flags into a discriminated union so the nonsense combinations can't exist, do that; a bug that can't be represented needs no test. Covering arrays are for the irreducible remainder — the legacy config, the third-party surface you don't control — and even there a covering array only guarantees a fixed interaction order across a fixed set of parameters, not every state your system can reach. The four-way bug slips a pairwise array; the bug that needs a specific sequence of transitions was never an "interaction" at all. Which raises the question: what if you could stop sampling — and prove the property holds across every reachable state?
Well. There is.
Step 3 — Model checking (formal verification)
One bug walks through every cut so far. It passes the type checker, survives the property test's few hundred rolls, and reads clean in review — because it isn't in any single line of code. It's in the order two events arrive in, the interleaving nobody drew on the whiteboard. It waits, then pages you at 3am, where it's most expensive to find. This is the bug that survives every test.
Model checking is built for exactly this bug. Property tests sample; a model checker walks the whole space. You hand it a precise description of your system, every state and every move, and it visits every reachable state, then drops the exact sequence that breaks your rule on your desk. There's a catch, and we'll get to it. It only ever explores the description you gave it, not your actual code, so it's only as good as how honestly that description matches what you shipped.
AWS has used TLA+ on S3 and DynamoDB since 2011. seL4 — a kernel proved correct down to the assembly — flies in drones. Their 2025 follow-up is blunt that it didn't scale past a whole toolkit. The lesson: pick the cheapest tool that exhausts your state space.
The smallest useful example fits on a napkin. Take a Todo with four states — active, done, archived, deleted — and one rule: once deleted, always deleted. TLC walks every reachable state and confirms it holds across all of them, not a handful of cases.
The payoff lands when a teammate adds an innocent-looking "undo delete"
transition. It compiles fine in any language; a property test might miss it. TLC
catches it instantly — and doesn't just say "failed." It hands back the exact
shortest sequence that breaks the rule: active → deleted → active. A model
checker doesn't return a red X; it returns a movie of how the system breaks.
Play it below: void an invoice and a payment already in flight lands late,
clawing it out of its grave stamped PAID. Whack the zombies as they pop —
you'll miss the ones you weren't watching — then hit the X-ray and watch the
model checker prove the one order that pays a dead invoice, every time:
Model checking
Whack-a-Ghost
Void an invoice and it's dead — buried. But a payment already in flight lands late, and the invoice claws out of its grave stamped PAID. Whack the zombies before they escape. (You can't watch all five graves at once…)
You don't need to read a line of TLA+ to get this.
On a Todo this looks like overkill — for plain CRUD, a discriminated union already catches almost everything a checker would. That's exactly why it gets waved off as academic, and exactly the wrong lesson: the bugs that survive every cheaper cut don't live in CRUD. They live in the next section's territory.
The spec got cheap to write — not cheap to trust
The cost of formal methods was never the checker — TLC and Z3 are free and finish in seconds at this scale. The cost was the spec: somebody with rare knowledge had to write it. An LLM now drafts it, and a lightweight checker like TLC or Z3 replaces the years-long proof for everything short of a spacecraft.
That barrier just collapsed, from two directions at once.
From above: LLMs write passable TLA+ now, and there are off-the-shelf Claude Code skills for exactly this loop — write the spec, run TLC, debug the violation. One discipline makes it safe: the checker, not the model, is the ground truth. An LLM will happily emit a plausible spec that's secretly the textbook's Paxos rather than your system. A wrong spec that goes red costs minutes; the quiet risk is the one that goes green, because a checker only vouches for the spec it was given. So generation doesn't remove the human — it moves your job from writing the spec to reading it: minutes, not years.
From below: if your state machine already exists in code, the spec doesn't
need to be written or generated — it can be extracted, mechanically,
with no model in the loop at all. Your aasm block, your XState machine,
your reducer already are the spec; a few hundred lines of extractor lift
them into a checker's input format. That's the chore I automated — you can try
the idea right now in the browser playground.
Either way the bottleneck moved — it didn't vanish, it changed shape. The LLM drafts the spec, turns your code into valid TLA+, and can even float candidate invariants for a checker to accept or refute. What it won't do is tell you which property is worth asserting — and that's the design act, the actual job. A 2026 benchmark (Can LLMs Model Real-World Systems in TLA+?) of frontier models writing TLA+ from real system code draws the line cleanly: they nail the syntax nearly every time, but a human still has to hand them the invariant to check — and even then the spec faithfully matches the running system less than half the time. The machine writes it down; you still decide what "correct" means and read what came back. That is the part that went from rare expertise to a habit you reach for — an afternoon, not a PhD. (A PhD was always overkill for checking whether a voided invoice can still be paid.)
The branches that survived review
The bugs that actually cost money are cross-field: an invoice marked voided while its payment_status still
reads succeeded — money captured against a cancelled bill, invisible to the
ledger. No single line is wrong; the two status fields just have no rule
forbidding the combination. Compose the two state machines and ask whether that
forbidden joint state is reachable, and you get back the shortest path that
leads there:
✗ VoidedIsNeverPaid — voided and payment=succeeded must not co-occur.
counterexample (reachable from the initial state):
status = draft, payment_status = pending
status = finalized, payment_status = pending
status = voided, payment_status = pending
status = voided, payment_status = succeeded ← the bug, as a reachable pathThat path is the whole point. You get the exact sequence of moves that lands on the illegal state, so the bug shows up with its reproduction steps already attached.
I didn't invent that example. I pointed a small checker at two widely-deployed open-source money systems — a billing engine and a commerce platform — and it surfaced exactly these contradictions. A reachable path is a candidate, not a bug — the checker works from the declared state machine, so a guard it can't see (a callback, a conditional write) can make a "reachable" state unreachable in the running system. That's not hand-waving: it happened to me, and it's the wall this technique hits. So a candidate earns the word "bug" only when you reproduce it against the real thing — which both of these were, each at the deployed layer (a payment-webhook handler, an admin route), each closing with a one-line guard.
And the bug class isn't mine to claim — an ISSTA 2011 study found cross-field data-modeling bugs of exactly this shape in two real Rails apps, fifteen years before I pointed a solver at it. These are latent bugs — surfaced by bounded checking, not live outages. They're also real money paths.
▶"Isn't this just model checking, or a schema linter?"
Fair — and the answer is in the framing. Lifting a model from code and checking it is
old: Rails data models were bounded-checked in 2011. But the verifiers you
can install today either make you hand-write the spec, or they auto-extract a model only
to hunt generic crashes — deadlocks, races, null derefs — not your business status
fields. And the "drift" tools that sound similar (prisma migrate diff,
active_record_doctor, Hibernate validate) check whether your schema matches the
database — not whether your validations match your constraints, a different drift one
layer up. The unoccupied bit: read the status machine out of your aasm/XState and prove
a forbidden cross-field state (un)reachable.
The check itself is a small open-source tool — extract the state machine you already have, ask whether a bad state is reachable (prune-states). But the tool is incidental; the point is to make these cuts land in your codebase before you write the next boolean.
Where the cheap cut stops
Every static technique here cuts one shape of bug: a state that can't be represented (the union) or can't be reached (the checker) — real, common, and in 2026 nearly free to fence off. But it sits on one side of a wall worth naming.
The dangerous bugs are usually dataflow: a field written on a path that skipped
the guard, a callback that re-transitions behind the model's back, a balance
recomputed wrong. prune-states hit that wall itself — an invariant came back a
false positive because a callback mutated state the declaration-level model
couldn't see. The bug isn't a reachable state; it's a write that reached a legal
state by the wrong path. Tracking that statically — write-site and consumer
analysis — is, in 2026, still a real build, not a one-liner.
So you don't reach for it — you change layers, from compile time to run time,
where the path stops mattering. A database CHECK fires on the write itself, so a
wrong path landing on an illegal row is caught however it got there — the
constraint checks the write, not the path that produced it. What still slips is the wrong-but-legal write — a
balance recomputed to a value the constraint accepts — and the concurrency that
breeds it. Those aren't shapes you forbid, they're races you make safe: an
idempotency key, a transactional outbox, the right isolation level.
So you don't give up at dataflow. You switch tactics: stop trying to prove the path is safe, and start watching the write itself. It's the same job either way. Name the invariant, then hand it to something more reliable than a careful programmer.
The political problem
We were building a CRM, and someone in a product meeting asked: what if we let users configure everything through a visual UI — triggers, actions, even the table schemas? Not just the values, the whole data model. The case was reasonable — customers want flexibility, and letting PMs configure it visually meant non-engineers could own a surface without filing a ticket. Nobody said no, because nobody in the room was thinking about state spaces. They were thinking about user agency, which is a genuinely good thing.
In practice, "users configure the data model" meant every combination of trigger, action chain, and schema was a product state we had to handle — not a large space, an unbounded one, a new topology per customer. We spent months on infrastructure for flexibility nobody needed. And the whole no-code argument that justified it evaporated the moment the tool for non-engineers to write code got good: now a PM describes a schema to an LLM and has it in thirty seconds. The complexity outlasted the argument that built it.
That's the shape of the political problem — not a wrong decision, but a reasonable argument made before anyone pulled a number. Out of the Tar Pit put the cost precisely: every bit of state you add doubles the possible states; complexity compounds, it doesn't sum. But a one-time "this adds unbounded states" argument is spent capital against an incentive structure that rewards whoever shipped the feature, not whoever counted its states. You don't win by arguing harder — you win by making the cost ambient.
Give the state space a budget the way you budget bundle size: a CI bot that comments "this PR adds two booleans to CheckoutProps: 32 states → 128." Ship it as information, not a gate — a gate gets disabled the first time it blocks a roadmap feature; a number in the PR survives long enough to change what "normal" means. It's cheaper than what comes after: bugs you can't reproduce, and the team you eventually staff to answer "what is this customer's setup even supposed to look like?"
Start cutting
You've done the static cuts — Part 1 — or start there first. This is the verification layer.
This week. Take the feature flags your test suite covers one at a time. Generate a covering array. Six rows instead of a million; the pair that breaks you lands in there by construction. If you can delete those flags into a discriminated union instead, do that first — a bug that can't be spelled needs no test.
This month. Pick one state machine you already have — AASM, XState, a reducer — and write down the cross-field invariant it assumes but never enforces. Check whether that state is reachable. By hand, or with a small checker. Give your state space a budget: a CI comment that surfaces "this PR adds two booleans: 32 states → 128" before anyone merges.
Each cut is small. Each deletes a class of bug for good. Stack a few and your weekends stop getting interrupted.
We opened Part 1 with a timeline forking out of control — yours, and now the model's. Two articles later: the bad states can't be spelled, the ones that survive can't be reached. A branch the type can't build can't ship; a state the checker can't reach can't break prod. Then nothing that passed every test still takes down prod.
Prune the timeline. One cut at a time.
References
▶Sources & further reading
- Murali Krishna Ramanathan et al., Piranha: Reducing Feature Flag Debt at Uber (ICSE 2020)
- D. R. Kuhn, D. R. Wallace, A. M. Gallo, Software Fault Interactions and Implications for Software Testing (IEEE TSE 2004) — the NIST interaction rule behind the covering-array section
- Unleash, When Feature Flags Interact
- Hillel Wayne, Learn TLA+ — the modern on-ramp
- Hillel Wayne, Why Don't People Use Formal Methods? (2019) — the spec-writing barrier the "spec got cheap to write" section argues just dropped
- Chris Newcombe et al., How Amazon Web Services Uses Formal Methods (CACM 2015)
- Marc Brooker et al., Systems Correctness Practices at Amazon Web Services (CACM 2025) — the ten-years-later follow-up: P, property-based testing, and deterministic simulation alongside TLA+
- Leslie Lamport, The TLA+ Home Page
- Can LLMs Model Real-World Systems in TLA+? (ACM SIGOPS, 2026) — where the "Etcd spec that was really the Raft paper's appendix" comes from; why the TLC check, not the model, is ground truth
- Travis Hance, Marijn Heule, Ruben Martins, Bryan Parno, Finding Invariants of Distributed Systems: It's a Small (Enough) World After All (NSDI 2021) — the first automated safety proof of Paxos
- Jaideep Nijjar, Tevfik Bultan, Bounded Verification of Ruby on Rails Data Models (ISSTA 2011) — mechanically extracts Active Record models into Alloy and finds real cross-field data-modeling bugs in two production Rails apps
- Maysam Yabandeh, Abhishek Anand, Marco Canini, Dejan Kostić, Finding Almost-Invariants in Distributed Systems (SRDS 2011) — mines properties that almost always hold from live system traces
- Ben Moseley, Peter Marks, Out of the Tar Pit (2006) — the canonical argument that state is the primary source of complexity
- Chris Hawblitzel et al., IronFleet: Proving Practical Distributed Systems Correct (SOSP 2015) — the 85-line spec / 3.7-person-year proof